去(2017)年科技部喊出臺灣正式進入「人工智慧(AI)元年」預計在五年內投入160億台幣。臺灣人工智慧學校在各大企業贊助及學研單位的投入教學下,經過三個多月密集培訓,已於今年四月底培訓出第一批五百餘名的技術及經理人員。
經濟部工業局也為了協助國內大型企業導入人工智慧技術,積極推動企業出題,新創團隊解題的「AI⁺ Solution Match人工智慧加值應用商業媒合」活動,並鼓勵各民間企業主動提出「AI主題式業界科專」。
在這種氛圍之下,身為創客的我們怎能錯過展現好點子落地的大好時機呢?接下來就為大家介紹如何取得及應用免費的AI實驗場域資源「Google Colaboratory」。
Google免費GPU資源Colaboratory
大家都說要玩AI先得準備個很貴的高級顯卡及伺服器才能跑得動,對於想入門練練手的人實在有點花不下去,就像想學開車的人不會先買一台法拉利,而是先去教練場學到一定程度後,再考慮一下預算及需求後才會依用途去買合適的跑車、房車、貨車、代步車甚至是二手車。
現在阮囊羞澀的各位有福了,Google旗下的實驗計畫Colaboratory (以下簡寫為Colab)提供了免費的NVIDIA K80等級GPU資源及虛擬機(Xeon 2.2GHz CPU*2)供大家使用,其中整合了Linux (Ubuntu)環境、Python、Jupyter notebook及TensorFlow等常用套件包,並允許大家安裝執行時所需套件包(如Keras、 OpenCV、PyTorch、MxNet、XGBoost等),只要有Google雲端硬碟帳號就可免費使用。

Google Colaboratory(圖片來源:https://goo.gl/5pwb4h)
當然不可避免地,這項免費資源並非毫無使用限制的,所提供的虛擬伺服器,目前只提供至少50G儲存空間和12GB(可用於訓練約2GB)的記憶體,使用時間僅可連續12小時(包含安裝軟體套件包、資料下載到虛擬機及訓練時間)。超過時間便會清掉使用中內容,有時還會因使用者過多造成連不上線或用到一半斷線,並不適合用在太大的模型及資料集訓練。
話雖如此,整體來說還是很方便家中沒有Linux + Python環境或電腦(筆電)CPU等級太低或沒有獨立顯卡的人及想學習人工智慧的新手練習使用。
何謂影像二元分類
在知名HBO影集「矽谷群瞎傳」第四季的第四集當中有個有趣的橋段,華人楊靖發明一款可拍照後辨識食物類型的APP叫「See Food」,展示時第一次拍熱狗成功辨識,眾人歡呼開始想像滿桌子的食物若都能辨識出來的話,這款APP肯定大賣。接著再拍了披薩後眾人等著APP回答「披薩」,可是APP卻回答「不是熱狗(Not Hotdog)」,眾人瞬間傻眼,「這只能辨識熱狗嗎?」楊靖回答:「是」,眾人大失所望、一哄而散。
然而,故事還沒完呢!竟有一家創投看上這個APP,要他改成偵測色情圖片中男生的小丁丁,這就是標準的「失之東隅,收之桑榆」。
雖然上面橋段的「Not Hotdog」只是虛構劇情,但現實中還真的人有把它實現出來,有興趣的人可到Apple APP Store下載Not Hotdog 。從上面故事中我們可得知影像分類的重要性,雖然影像二元分類(是或不是)的用途較窄些,但若能大量(數千到數百萬張)標註影像的分類,經過訓練後可令影像精準地分類,那就有可能產生一些獨特的商機。

Not Hotdog APP螢幕擷圖(圖片來源:https://goo.gl/Q6d7NT)
用Colab實現影像二元分類
為了讓大家能快速上手,在此整理了一段完整的代碼並有詳盡的原理解說及註解,只要依著下列步驟就可快速建構出一個二元分類的影像分類系統,當然也包括如何用自定義的資料集進行訓練及推論。代碼主要包括以下四個主要步驟,另外還有更進一步的細節說明,如下所示。
1. 取得及建構訓練數據(Training Dataset)
- 下載資料集
- 資料集解壓縮
- 檢視資料集
- 自定義資料集及掛載
2. 建構一小型深度學習模型(Training Model)
- 卷積網路模型
- 輸入圖像尺寸正規化
- 模型架構及訓練參數說明
- 模型配置及訓練優化設定
- 數據預處理
3. 訓練及驗證模型準確度(Validation Accuracy)
- 訓練及驗證模型
- 評估模型的準確性和損失
4. 應用深度學習訓練成果進行推論(Inference)
- 推論
- 可視化表示
了解了相範例的學習目標後,可以至https://goo.gl/SqigfE下載image_classification.ipynb 到您的Google雲端硬碟,雙擊後選擇以「Colaboratory」開啟,就可以開始享受Colab提供的免費GPU運算資訊。執行時,請按【Shift+Enter】進行單步執行並自動跳至下一行;若想一次全部運行本範例所有代碼,可按【Ctrl+F9】。接下來就簡單為大家介紹主要步驟的工作內容。
建構數據集
為了練習「建構數據集」這個題目,我們首先必須要有資料集,但實在不容易在短時間內收集到數千張的影像,好在知名人工智慧比賽平台Kaggle上有一個「Dogs and Cats」的影像分類比賽,它提供了大量的貓狗影像,以供測試「深度學習」算法(模型)的正確性。
Google為方便大家測試Colab,再將其減量到訓練用影像貓狗各1000張,驗證用影像貓狗各500張,其資料集樣本大致上如下圖所示。影像沒並沒有特定尺寸,貓狗在影像中佔的面積比例、種類、色彩、數量、位置、明暗、遮蔽、背景複雜度也都沒有限制。

Kaggle提供的「Dogs and Cats」資料集樣本(圖片來源:OmniXRI整理製作)
卷積神經網路模型
這個範例中,主要利用TensorFlow及Keras建構出一個小型的卷積神經網路(Convolution Neural Network, CNN),共有三層卷積層(包含ReLu及Max Pooling),每個卷積層皆用3×3的濾波器進行卷積動作,三層分別提取16, 32及64組濾波器。接著展開成獨立節點後,再加入二層全連結層,分別為512及1個節點,而最後得到的那一個節點加上Sigmodid函數即為最終輸出的結果,合計共有9,494,561個參數待訓練。
輸出的結果值會介於0.0 ~ 1.0,當值越接近1.0時圖片為狗的機率越高,反之輸出值越接近0.0時圖片判定是貓的機率越高。雖然這個模型雖然不大,但可適用各種圖像的二元分類問題,大家可試著導入自己準備的圖像進行測試。完整模型架構可參考下圖。
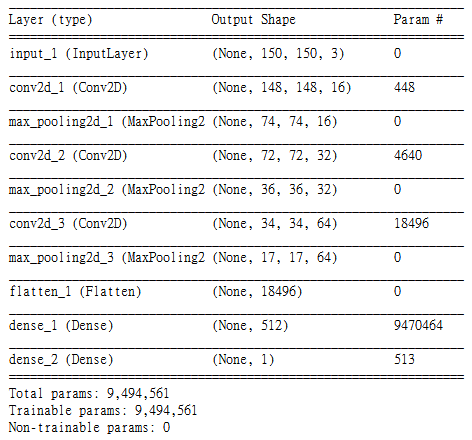
卷積神經網路架構 (OmniXRI整理製作)
訓練及驗證
下方圖左為正確率,圖右為損失率,橫軸代表迭代次數,縱軸代表正確(或損失)率;藍線代表訓練集結果,而綠線代表驗證集結果。從圖中可看出藍線在第十次正確率就已超過0.97(97%),而損失率已趨近0,但綠色的線正確率卻沒有繼續變高,數值約接近0.7(70%),損失率反而逐漸增高。這表示訓練過程已造成過擬合(over fitting)的狀況,需要加入更多不同樣態及更多數量的資料集再重新訓練才能改善。
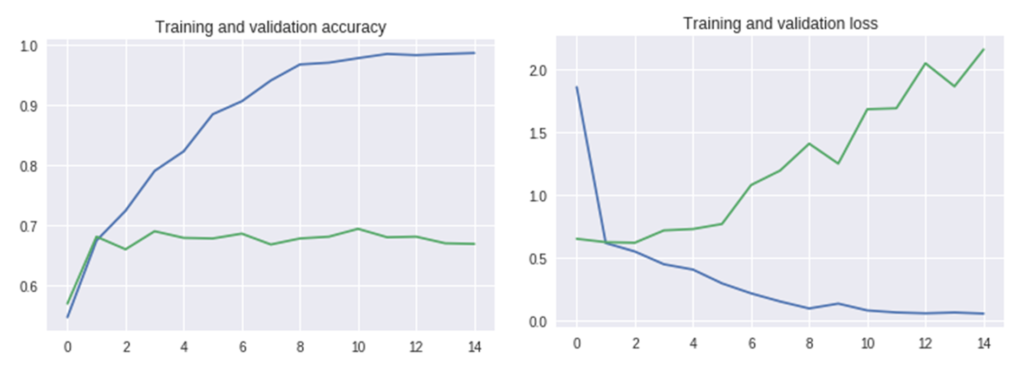
左:訓練及驗證準確性,右:訓練及驗證損失(OmniXRI整理製作)
推論結果
接著就可利用前面訓練好的模型(model)來加以推論(或稱為預測)。首先提供一張圖片,並將圖像資料正規化(150x150x3, Float32),接著進行推論,最後會得到圖像分類結果分數,而分數越接近1.0則表示是狗的機率越高,反之越接近0.0則越可能是貓。我們可以另設幾個自定義門檻值來區隔分類結果,比方說「這是狗」、「這可能是狗」、「這可能是貓」、「這是貓」等不同結果描述。
為了讓大家更了解深度學習模型運作方式,將各層運作結果輸出到特徵圖中,再逐一秀出。如下圖,最上面為原始輸入影像正規化後的結果圖,再來才是真正導入輸入層的資訊,尺寸為150×150共有3組(RGB三通道)。
第一卷積層共產生16個特徵圖,conv2d_1尺寸為148×148,max_pooling2d_1尺寸為74×74;第二卷積層共產生32個特徵圖,conv2d_2尺寸為72×72,max_pooling_2為36×36;第三卷積層共產生64個特徵圖,conv2d_3尺寸為34×34,max_pooling_3為17×17;最後的全連結層(dense)則為單一節點資訊,不易以圖形方式表示,故忽略不處理。
從各層特徵圖中可看出,隨著影像尺寸縮小其被激活的像素越來越少,甚至完全不輸出(全黑),表示其特徵已被某些卷積(濾波器)給凸顯出來。對於我們所需的圖像分類(辨識)能力也逐漸增強了。
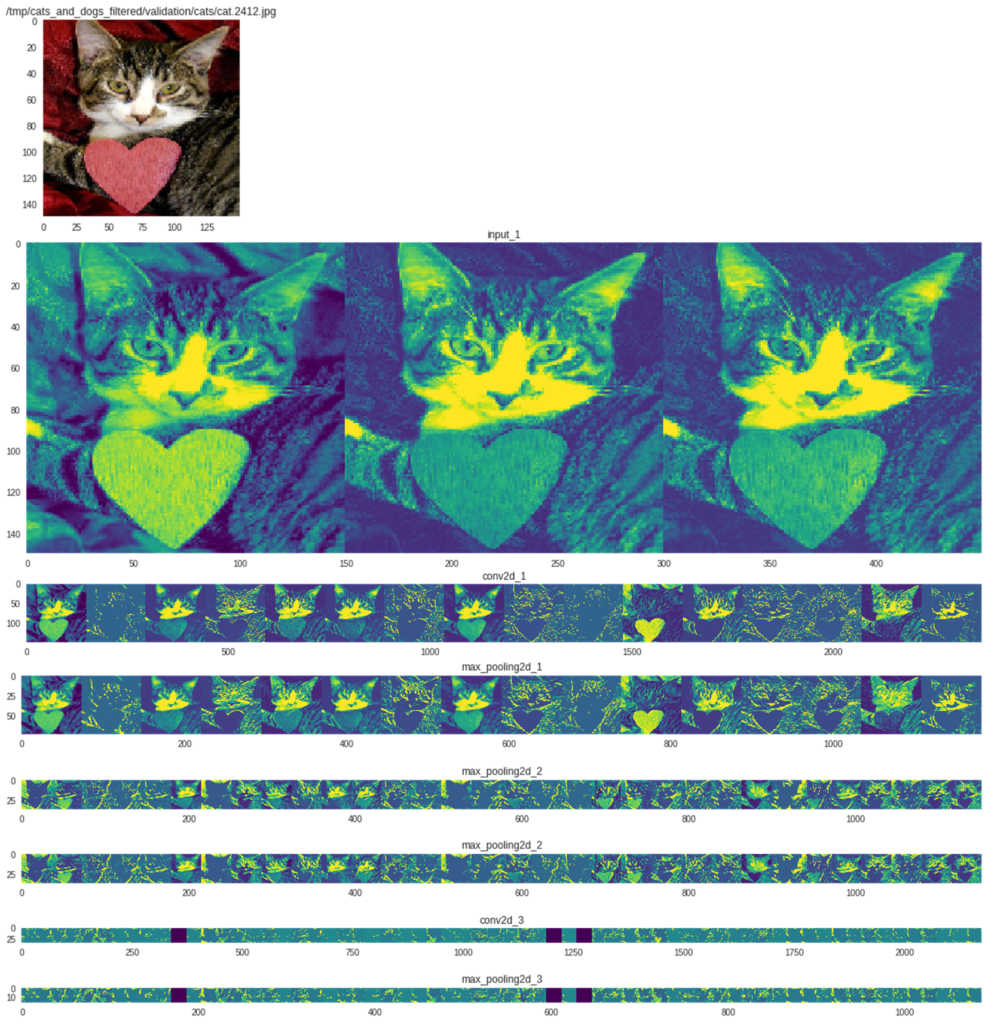
推論結果可視化 (OmniXRI整理製作)
結論
Google Colaboratory這項免費的雲端GPU資源實在很方便剛入門的伙伴進行「深度學習」(一語雙關),它不會因為個人電腦(筆電)的配備等級不同,而影響模型訓練及推論的效能。同時,可輕易的分享代碼給其它想學的人,對開源社群更是一大助力。希望不久的將來有更多伙伴能一起加入研究及分享,讓更多人工智能的應用能加速落地。
完整代碼及說明,請參閱OmniXRI Github
(本文同步發表於歐尼克斯實境互動工作室(OmniXRI);責任編輯:葉于甄)





留言
張貼留言